Customer churn prediction: Using data for smarter retention
Published on April 23, 2025/Last edited on November 11, 2025/19 min read


Team Braze
Customer churn is one of the clearest signals that something’s not working, but spotting it early is rarely straightforward. Churn rates vary widely across industries, business models, and growth stages, which means there's no universal benchmark for success. Even global brands like Netflix aren’t immune to fluctuations, with measurable changes from one year to the next.
What businesses can control, however, is how they respond. Predictive modeling has made it possible to identify customers at risk of churning before they turn into lost customers—giving brands the opportunity to act fast and stay relevant.
In this guide, we’ll walk through the fundamentals of churn prediction—from the data that powers it to the AI models that make it work—plus practical tips to turn insights into action.
Contents
- What is churn?
- What is churn prediction?
- Types of churn
- How does churn prediction work?
- What data needs to be collected and managed to predict churn?
- Churn prediction models
- Challenges in churn prediction
- Tips for implementing a churn prediction strategy
- How BrazeAI™ can help you retain your customers
- Final thoughts
- Churn prediction FAQs
What is churn?
Customer churn is what happens when someone stops buying from your brand or using your products and services. Small shifts in behavior can signal growing disengagement, and the earlier you notice them, the more time you have to respond.
Here are some of the most common red flags:
- A noticeable drop in engagement with your emails, push notifications, SMS, or other messaging channels
- More frequent cart abandonments
- Longer gaps between key actions, like opening your app, visiting your site, redeeming loyalty rewards, or making a purchase
- App uninstalls
- Unsubscribes or opt-outs from your communications
In general, if a customer starts breaking their usual engagement patterns—like skipping their regular monthly order or opting out of your messages—it’s worth paying attention. These changes don’t always mean churn is guaranteed (sometimes unsubscribing is just a sign of message fatigue), but they can be useful signals that someone’s drifting.
Being alert to these shifts gives you a chance to step in, re-engage thoughtfully, and strengthen the relationship before it slips away.
What is customer churn prediction?
Churn prediction is the practice of spotting the warning signs before it’s too late. For example, brands can use machine learning and behavioral data to identify which customers are likely to disengage—and then take action while there’s still time.
Churn prediction models typically rely on a mix of customer behavior data, transaction history, engagement data, and more. They can spot trends and assign churn risk scores to individual users or segments, making it easier to prioritize who needs attention and automate the kind of actions that help to prevent churn.
For eCommerce businesses, this might mean spotting customers who fall outside the typical buying cycle. For apps or subscriptions, it could be a drop in engagement or a skipped renewal. Either way, the goal is the same: Identify customers that are most likely to churn before it happens.
Why is customer churn prediction important?
Acquiring a new customer often costs significantly more than retaining an existing one. Beyond the impact on customer retention, churn prediction also helps businesses use their time and resources more effectively. Instead of spreading efforts across the entire user base, teams can zero in on high-risk customers and design campaigns with purpose. More than a data point, customer churn prediction is a competitive edge and helps marketers increase their ROI.
Types of churn
Not all churn looks the same, and understanding the different forms it can take helps brands respond more effectively. Here’s a breakdown of the most common types:
Voluntary churn
This is when a customer makes an intentional decision to stop using your product or service. It could be due to dissatisfaction, changing needs, or simply finding a better option elsewhere. Whatever the reason, this kind of churn signals a deeper need for insight into the customer experience.
Involuntary churn
Involuntary churn often flies under the radar. It happens when payments fail due to expired cards or processing errors—not because the customer wants to leave. With the right systems in place, this kind of churn is usually preventable through automated payment reminders or smart retries.
Active churn
Similar to voluntary churn: A customer chooses to cancel and follows the process to do so. It’s often the most visible type, offering a clear signal, but also a key opportunity to gather feedback and understand what pushed them to leave.
Passive churn
Like involuntary churn, his type of churn is quieter. It happens when a customer doesn’t take any direct action to cancel, but their subscription ends or lapses without renewal. It’s common in subscription models and can be reduced with timely nudges or re-engagement campaigns.
Revenue churn
Sometimes, churn doesn’t involve losing a customer entirely. Revenue churn occurs when someone downgrades their plan or reduces their spend. They’re still a customer, but the value they bring drops, so it’s just as important to track and address.
Customer churn
This is the umbrella term for when users or subscribers leave altogether. It reflects the total number of customers lost over a given period and is a key metric for understanding growth, retention, and the health of your customer base.
How to predict customer churn
Churn prediction uses historical data analysis to spot early signals of customer drop-off. By identifying these patterns, brands can identify users and take action before loyalty fades. Here’s how the process typically comes together:
1. Gather meaningful customer signals
Pull together data from across the customer journey—everything from purchase history to support tickets and usage habits. The goal is to capture a well-rounded view of how people interact with your brand to identify better signals for churn.
2. Get your data in shape
Before analysis can begin, it’s good to have a strong data foundation. This could include tidying up inconsistencies, filling in blanks, aligning formats, and making sure everything’s ready for modeling.
3. Surface the right insights
Not all data points are useful. Identify smart signals—like session frequency, engagement drop-offs, or total spend—that tell a clearer story and lead to more accurate predictive outcomes.
4. Train your prediction engine
Once the dataset is ready, it’s time to build the churn model. AI/ML techniques like logistic regression, decision trees, neural networks, and boosting algorithms are used to spot patterns and assign churn likelihood, many of which are powered by advanced machine learning algorithms.
5. Check your churn model’s pulse
A prediction churn model is only helpful if it performs well. Testing accuracy and reliability using metrics like recall and precision helps make sure the insights you’re getting are actionable and accurate.
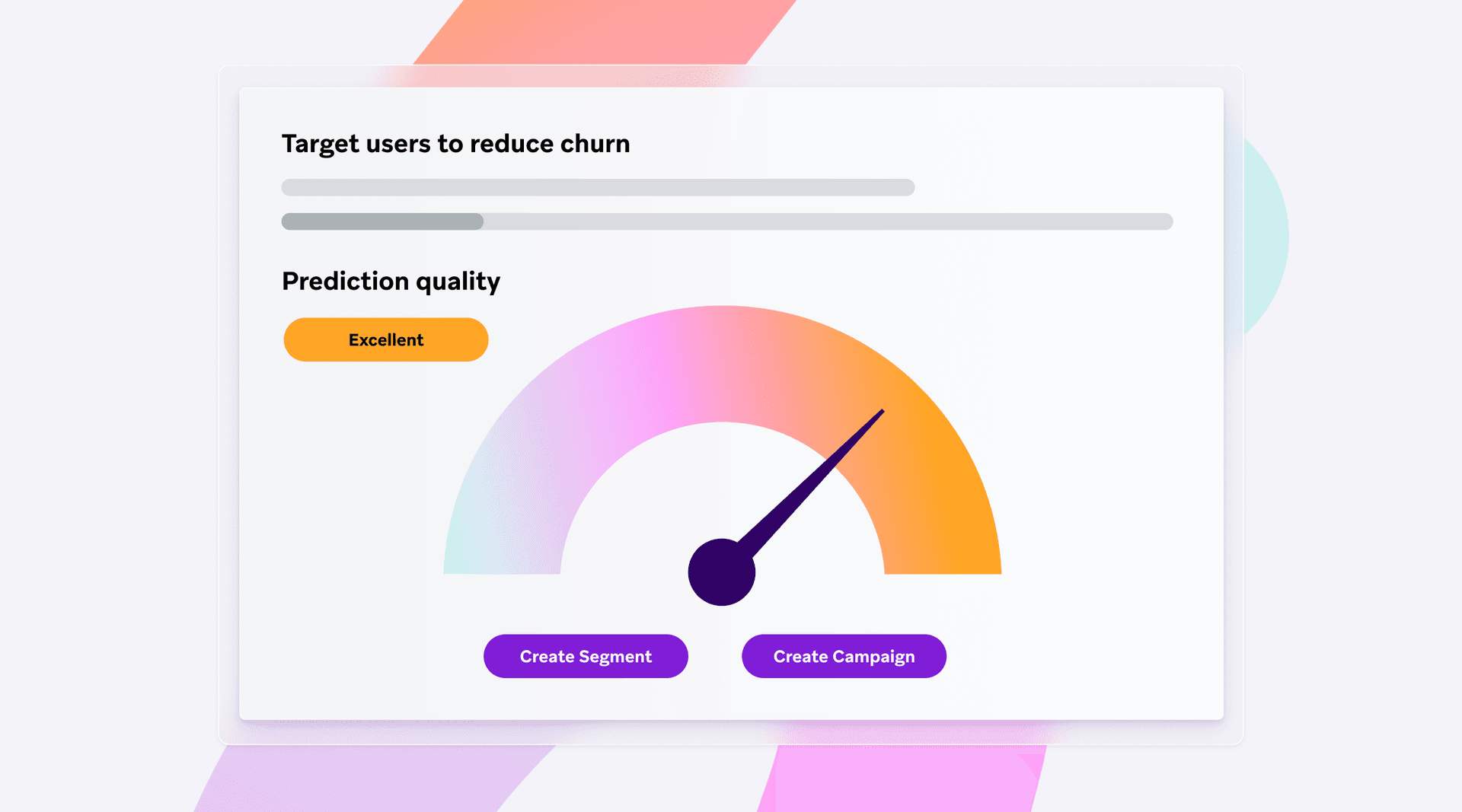
6. Put your churn model to work
After testing, the model can be rolled out and used in real time. But this isn’t a once-and-done task. To stay effective, the model needs regular check-ins, updates, and recalibration as customer behavior and business conditions evolve.
What data needs to be collected and managed to predict churn?
Churn prediction starts with data—the right kind, in the right context. To build reliable models that flag churn risks early, businesses need a mix of behavioral, transactional, and contextual insights. Here’s what that typically includes:
Customer behavior
How customers interact with your product reveals a lot about their likelihood to stick around. Tracking things like session frequency, time spent in-app, feature engagement, and activity sequences can help surface early signs of disengagement. A drop in usage or a sudden change in habits? That’s often where churn starts.
Product usage
Usage data zooms in on how customers experience the product over time. It highlights which features are most (or least) used, how often customers return, and whether their engagement is trending upward or declining. Consistent usage often points to satisfaction. Fluctuations or inactivity may suggest otherwise.
Purchase and payment history
Tracking what customers buy, how often they buy it, and how their average spend changes over time can reveal key churn signals. A slowdown in purchases or a shift to lower-value transactions might suggest waning interest or budget constraints. Payment methods and subscription renewals can also surface friction points.
Customer interactions
Support tickets, feedback, and communication history add another layer to the picture. Frequent complaints, unresolved issues, or negative customer feedback can all hint at growing dissatisfaction. On the flip side, high engagement with support may also reflect a loyal customer who just needs better service. Bringing together these customer interactions builds a more complete picture of each user’s experience.
To go even further, some businesses also bring in external data—like social media signals or competitive insights—to strengthen their models. But at its core, effective customer churn prediction relies on understanding your customers’ behaviors, preferences, and challenges through the data you already have.
Churn prediction models
Predicting churn using proven predictive models uncovers patterns in customer behavior that point to future risk. With the rise of AI and machine learning, businesses now have access to powerful models that can analyze vast datasets, find subtle signals, and deliver smarter predictions. These churn prediction models each offer different strengths depending on the complexity and size of your data.
Here’s a look at the most common churn prediction models, and where each one fits best:
Logistic regression
One of the most widely used techniques, logistic regression predicts the probability of churn as a binary outcome: Stay or go. It works by analyzing historical data and identifying which variables—like service complaints, purchase frequency, or usage drops—are most closely linked to churn.
Good for: Teams looking for a simple, interpretable churn model that highlights the “why” behind churn.
Watch out for: It assumes a linear relationship between variables, so it may miss complex interactions or nonlinear trends.
Decision trees
Decision trees split data into smaller branches based on customer attributes and behaviors, building a clear, visual path toward predicting churn. They're intuitive and flexible, making them a strong choice for understanding the steps that lead to customer loss.
Good for: Businesses that want transparency and the ability to explain predictions to stakeholders.
Watch out for: Trees can overfit the data if they get too detailed or complex, meaning that they memorize the training set so closely, that it makes them less effective on new datasets.
Neural networks
Neural networks mimic the brain’s structure to process complex relationships between data points. They’re especially good at picking up subtle signals and handling vast amounts of diverse data—ideal when churn drivers aren’t obvious or linear.
Good for: Large datasets with intricate customer behavior, such as streaming, or eCommerce.
Watch out for: These models are harder to interpret and training them takes more time, more data, and more computing power.
Random forests
Random forests are an ensemble method that builds multiple decision trees on different data subsets and averages their results. This approach reduces overfitting and improves accuracy.
Good for: Companies with varied customer types and behaviors.
Watch out for: These models can become overly complex, data can be harder to interpret, and depending on the number of trees, might need far more time and memory and therefore more expensive.
Gradient boosting (e.g., XGBoost, LightGBM)
Gradient boosting trains models in sequence, with each new model learning from the errors of the last. It’s powerful for handling high-dimensional data and capturing complex relationships.
Good for: Teams looking for high performance and precision in their predictions.
Watch out for: Boosting methods can be more sensitive to noise–random data, errors, or unwanted variations–which can produce irrelevant or incorrect information, and so more time is needed to accurately train.
Support Vector Machines (SVMs)
SVMs find a hyperplane or decision boundary that best separates churners from non-churners. They’re well-suited to complex, high-dimensional data.
Good for: Datasets with a clear distinction between churn and non-churn segments.
Watch out for: SVMs are more technical and may require careful tuning to perform well.
Ensemble models
Ensemble methods combine the outputs of multiple models—whether trees, neural networks, or regressions—to boost accuracy and stability. By aggregating predictions, they offset the weaknesses of individual models and capture a broader view of churn risk.
Good for: Complex, noisy datasets where no single model performs well on its own.
Watch out for: More complexity and higher resource requirements, along with less transparency around the “why” behind predictions.
Challenges in churn prediction
Predicting churn can unlock major retention gains, but getting there isn’t always simple. From data quality to regulatory demands, businesses face a range of hurdles when trying to turn raw customer data into reliable churn insights.
Here are some of the most common challenges to watch out for:
Data quality and integration
A churn model is only as good as the data it’s built on. Incomplete, outdated, or inconsistent data can lead to misleading predictions. Gathering high-quality (and preferably zero-party and first-party data) is step one, but stitching it together across tools and touchpoints is just as critical. Without strong integration, and unifying of your datapoints, your view of the customer stays fragmented, limiting the model’s potential.
Choosing the right data sources
Churn signals come from a wide range of sources—transactions, support tickets, product usage, social media sentiment, and more. But more data doesn’t always mean better data. The challenge is identifying which variables truly matter and filtering out the noise.
Keeping up with customer behavior
Customers aren’t static. Preferences shift, markets evolve, and external factors—from seasonality to economic changes—can affect buying patterns. What predicted churn last quarter might not apply now. This makes it important to retrain models regularly and adjust inputs as behavior shifts.
Privacy and compliance
Working with customer data means operating within the boundaries of privacy regulations like GDPR. That means practices such as gaining clear consent, anonymizing sensitive data where needed, and building secure systems that protect customer information. Also, it’s important to deliver value to the customer when asking for or using their data.
Interpreting the model
Some of the most powerful models can also be the hardest to interpret. If you can’t explain why a model flagged someone as high-risk, it’s harder to act on that insight or explain it to internal stakeholders. In highly regulated industries, this lack of transparency can also pose a compliance risk.
Operationalizing predictions
A churn score on its own doesn’t reduce churn—it’s how you use it that counts. Turning predictive insights into actions across marketing, support, or product teams takes planning. You’ll need clear workflows, cross-team alignment, and the right tools to translate signals into results that reduce your churn rate.
Avoiding overfitting
A model that fits perfectly to your historical data isn’t always the best one. If it’s too tailored to past patterns, it might struggle to handle new behavior. Avoiding overfitting is a key part of building models that generalize well—and deliver useful predictions in the real world.
Watch out for data leakage
In supervised churn prediction, models learn from historical data to forecast future behavior. But if that training data includes information the model wouldn’t have access to during real-world prediction, the results can become misleading. This issue—called data leakage—gives the model an unfair advantage during training by exposing it to outcomes it shouldn’t yet “know.”
The model looks highly accurate during development, but once deployed, its performance drops because it was trained on data that won’t be available in practice. Avoiding data leakage is crucial for building reliable, real-world predictive models.
Handling unexpected shifts
Even the best model can’t see everything coming. Market disruptions, product changes, or competitor moves can all introduce variables your model hasn’t encountered before. That’s why customer churn prediction should be part of a broader strategy, not a one-and-done solution.
Tips for implementing a churn prediction strategy
There’s no universal churn model that works for every business, and that’s a good thing. The most effective strategies are the ones shaped by your unique goals, customer base, and creative strategy. Here’s how to approach churn prediction in a way that makes sense for your business:
Make sure you are building the campaigns to bring them back once identified
Before diving into models and data, take a step back. What keeps your customers returning? Why do they value your brand? Understanding the motivations behind customer loyalty, and the triggers for churn, helps you frame your strategy with the right focus.
Identify the right data
Churn prediction is only as strong as the data behind it. Think about the touchpoints that matter most in your customer journey, whether it’s transaction history, support tickets, app engagement, or social sentiment. Focus on collecting data that’s relevant, reliable, and accessible across teams.
Collaborate across departments
Customer experience doesn’t live in a single team. Sales, support, product, marketing, and data teams can all hold valuable insight into churn patterns. Loop them in early, both to identify key data sources and to make sure your strategy is technically feasible and cross-functionally aligned.
Pick the right churn model for your needs
Your choice should reflect your goals, data maturity, and the level of complexity you’re equipped to manage.
Make sure your data is in the right place
Before modeling begins, it’s important that your data is actionable. Solid preparation at this stage helps lead to more useful outcomes.
Build, test, and validate
Once your model is in place, run it against control audiences, historical data and real-world scenarios. Look for both accuracy and practicality. Does the model correctly identify high-risk customers? Can you act on the insights it provides?
Keep it current
To stay relevant, your churn model needs regular updates. Retrain it on fresh data, monitor performance over time, and make refinements as needed to keep it aligned with your business reality.
Take action on your insights
A churn prediction model doesn’t solve churn on its own—it gives you a head start. Use what you learn to shape smarter strategies, like targeted retention strategies that re-engage at-risk customers with timely, relevant messaging. Try refining onboarding, or adjust product features too. The real value comes when predictions turn into practical, proactive moves.

How can BrazeAI™ Predictive Churn help you retain customers?
Keeping customers is easier when you can anticipate what they need—and even easier when you know who’s about to walk away. That’s where Braze Predictive Churn and events step in. By using machine learning to identify which users are most at risk of disengaging, Braze gives marketers the insight—and the tools—to take action before it’s too late.
Powered by BrazeAI™, Predictive Churn analyzes real-time customer behavior to flag patterns that often lead to churn. These predictions don’t just sit in a dashboard—they’re built directly into your Braze workflow, so you can use them in audience segmentation, message personalization, journey orchestration, and campaign targeting.
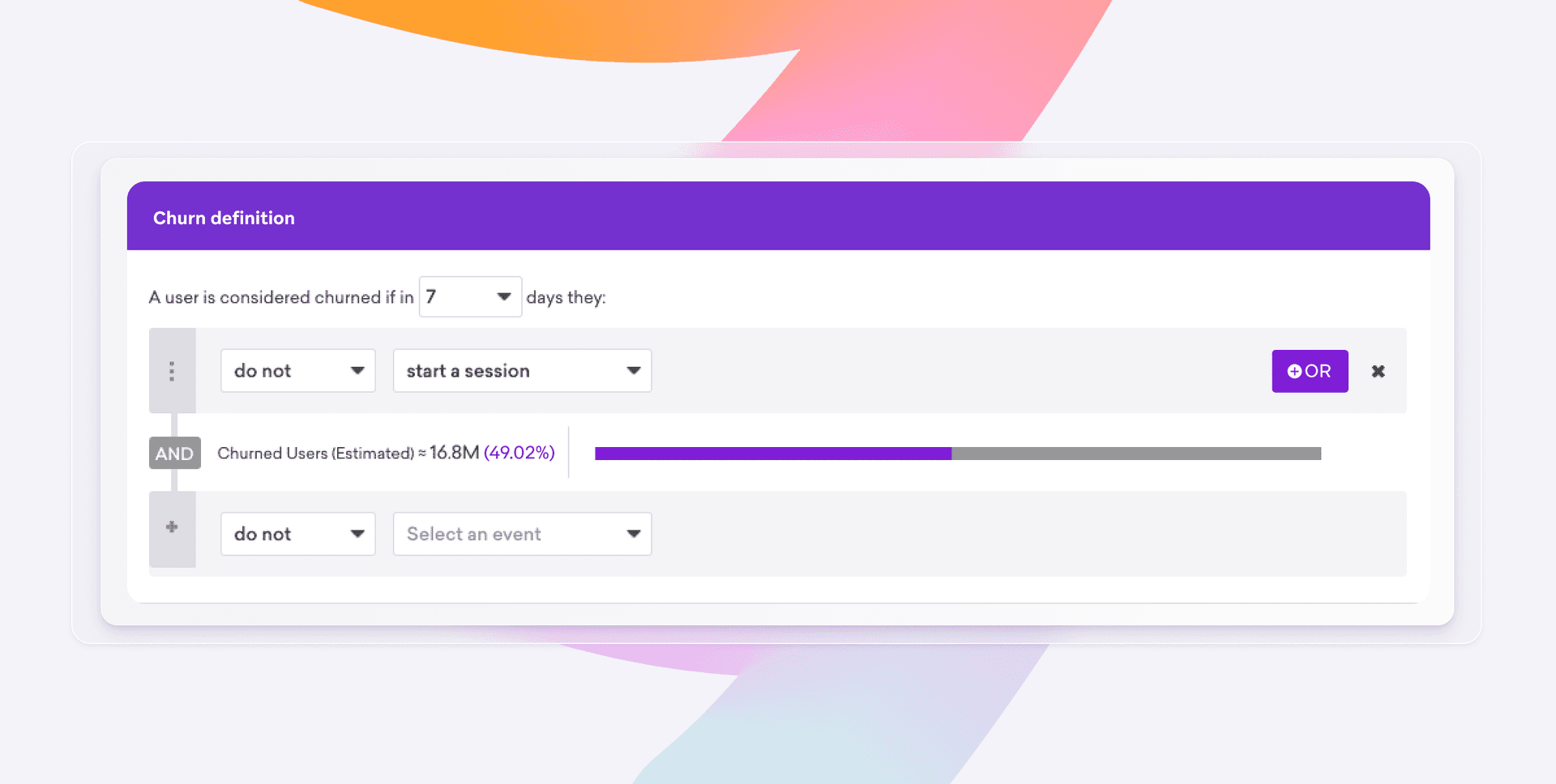
Let’s say a customer starts to change their behaviors, maybe one, who used to open your app weekly suddenly goes quiet. With Predictive Churn, you don’t need to wait for a full drop-off. You can identify the customers that are showing behaviors of churn and build a campaign around them - whether it is a retention message, a win-back offer, or even an in-app prompt to check in—meeting that customer where they are, with relevance and care.
Here are other ways Braze helps with reducing churn and improving retention:
- Smarter targeting, no data science team required: Built right into your dashboard, Predictive Churn uses machine learning models trained on each unique user behavior, event and historical data—so you’re not relying on generic benchmarks.
- Real-time insights, always in motion: Customer profiles and audience segments update based on live behavior and event data. That means your churn predictions keep current, and your engagement strategies can adjust in the moment.
- Retention reports: Braze Retention Reports allow marketers to measure and visualize user retention associated with specific campaigns or customer journeys. These reports provide insights into how users engage over time, so you can identify when engagement begins to decline, and evaluate the effectiveness of different message variants. Conversion correlation reports also use BrazeAI™ to uncover correlations between customer attributes and outcomes.
- Seamless activation across channels: Whether you’re reaching customers via email, push, SMS, or in-app messages, Braze makes it easy to tailor your outreach based on churn risk—so your team can focus less on manual segmentation and more on creating meaningful touchpoints.
- Scale with personalization: With BrazeAI™, it’s possible to personalize creative and messaging at scale—matching tone, timing, and content to each individual’s preferences, past behaviors, and likely future actions.
- Stronger outcomes, less guesswork: BrazeAI™ takes care of the heavy lifting behind the scenes, automating decisions that used to take hours of testing and intuition. Marketers can move faster, experiment more freely, and focus on what drives real business results.
Final thoughts
Churn is an inevitable part of doing business, but letting it go unchecked isn’t. With the right data, thoughtful modeling, and a strategy rooted in real customer insight, it’s possible to predict customer churn with accuracy and act before it's too late. The goal isn’t just to keep customers longer, it’s to reduce your churn rate by creating experiences that deepen loyalty and build trust over time.
That’s where Braze comes in. With Braze Predictive Churn, you can identify high-risk customers using built-in machine learning models—no data science team required. These predictions update automatically based on user behavior, making it easy to build responsive journeys that speak directly to customers who need a nudge. Whether you’re sending a timely offer, surfacing helpful content, or tailoring your messaging to re-engage lapsed users, Braze gives you the tools to turn insight into impact.
Customer churn may be complex, but with the right platform behind you, acting on it doesn’t have to be.
Forward-Looking Statements
This blog post contains “forward-looking statements” within the meaning of the “safe harbor” provisions of the Private Securities Litigation Reform Act of 1995, including but not limited to, statements regarding the performance of and expected benefits from Braze and its products and features. These forward-looking statements are based on the current assumptions, expectations and beliefs of Braze, and are subject to substantial risks, uncertainties and changes in circumstances that may cause actual results, performance or achievements to be materially different from any future results, performance or achievements expressed or implied by the forward-looking statements. Further information on potential factors that could affect Braze results are included in the Braze Annual Report on Form 10-K for the fiscal quarter ended January 31, 2025, filed with the U.S. Securities and Exchange Commission on March 31, 2025, and the other public filings of Braze with the U.S. Securities and Exchange Commission. The forward-looking statements included in this blog post represent the views of Braze only as of the date of this blog post, and Braze assumes no obligation, and does not intend to update these forward-looking statements, except as required by law.
Churn prediction FAQs
How accurate is predictive churn?
Predictive churn models can be highly accurate when built on quality data and regularly updated, but results may vary depending on the industry, customer behavior, and available inputs.
What is churn score in prediction?
A churn score is a probability value that indicates how likely a customer is to stop engaging with your brand within a given timeframe.
What does churn mean?
Churn refers to when a customer stops using your product or service, either by cancelling, becoming inactive, or not returning.
How does Braze Predictive Churn differ from other churn models?
Braze Predictive Churn offers a dynamic, integrated, and customizable approach to understanding and addressing customer churn compared to traditional models:
- First-party data utilization: Braze collects first-party customer data based on actual customer actions, allowing for continuous feedback and optimization of the churn model over time. This contrasts with point solutions that often require complex integrations with external data warehouses.
- Cross-channel capability: The model can incorporate data from different channels to influence predictions and actions across other channels. This flexibility allows businesses to engage customers through their preferred channels, enhancing the effectiveness of retention strategies.
- Customizability: Braze Predictive Churn can be tailored to define churn based on specific events that matter to your business, such as unsubscribes or deferred payments. Additionally, it allows for the creation of customizable churn audiences, helping to identify the exact segments of customers at risk of leaving.
- Integration with BrazeAI™ Functionality: The predictive churn model can be paired with other BrazeAI™ features, enabling businesses to not only identify customers likely to churn but also to generate targeted content. This includes experimenting with different message variants or offering recommendations, so that communications are sent at the optimal time and through the best channels.
Related Tags
Be Absolutely Engaging.™
Sign up for regular updates from Braze.