Exploring the technical side of ingesting data into Braze
Published on May 28, 2026/Last edited on May 28, 2026/12 min read

Matt D’Abreu and Maciej Olko
Matt D’Abreu, Solutions Architect, Braze and Maciej Olko, Associate Growth Engineer, BrazeContents
Data is central to marketing today, allowing brands to power relevant, highly personalized experiences for their customers at scale on a global level. But while we’ve seen a strong focus on data collection and data privacy over the past five years, there hasn’t always been as much focus on an equally important component of the data equation—namely, data management, which refers to the ways companies control how data moves in and out of the digital systems that provide the foundations for their customer engagement programs.
Braze is a real-time, event-driven customer engagement platform designed to process and act on behavioral and transactional data as it is received. This allows brands to understand how users interact across digital touchpoints such as websites, mobile apps, and backend systems, and to immediately respond with personalized messaging and experiences.
That’s why we prioritized making it easy to surface data from the Braze platform by building our high-volume data export feature, Braze Currents, and adding support for Snowflake Secure Data Sharing. It’s also why we offer a suite of different data ingestion options for brands looking to leverage data using Braze to enhance their customer engagement efforts. To provide you with a richer understanding of how to pass information into the Braze platform, let’s look at the four main ways that Braze ingests data and the nuances of each approach.
1. Cloud Data Ingestion
Cloud Data Ingestion (CDI) allows brands to integrate data directly from their data warehouse into the Braze platform for further segmentation, message targeting, and personalization. With CDI, brands can automatically sync data between the platforms on the schedule of their choice. When a sync runs, Braze connects to your brand’s data warehouse, pulling in new data and updating relevant user profiles within Braze, supporting more relevant, effective customer experiences.
What data sources does CDI support?
Because the Braze data model supports flexible user attributes, including nested objects and array-like structures (where supported within Braze user profile fields and custom attributes), brands can sync both structured and semi-structured data from supported sources. This reduces the need for complex transformation pipelines and helps teams activate warehouse data more efficiently for segmentation and personalization use cases.
This feature is designed as a warehouse-native ingestion pattern for long-term data activation. Today, CDI supports integrations with multiple source types, including:
- Data warehouses such as Snowflake, Google BigQuery, Amazon Redshift, Databricks, and Microsoft Fabric
- File storage solutions such as Amazon S3 for file-based ingestion workflows
- Connected sources, a zero-copy alternative that allows Braze to query data directly from your warehouse or storage layer to build segments without ingesting or duplicating the underlying data
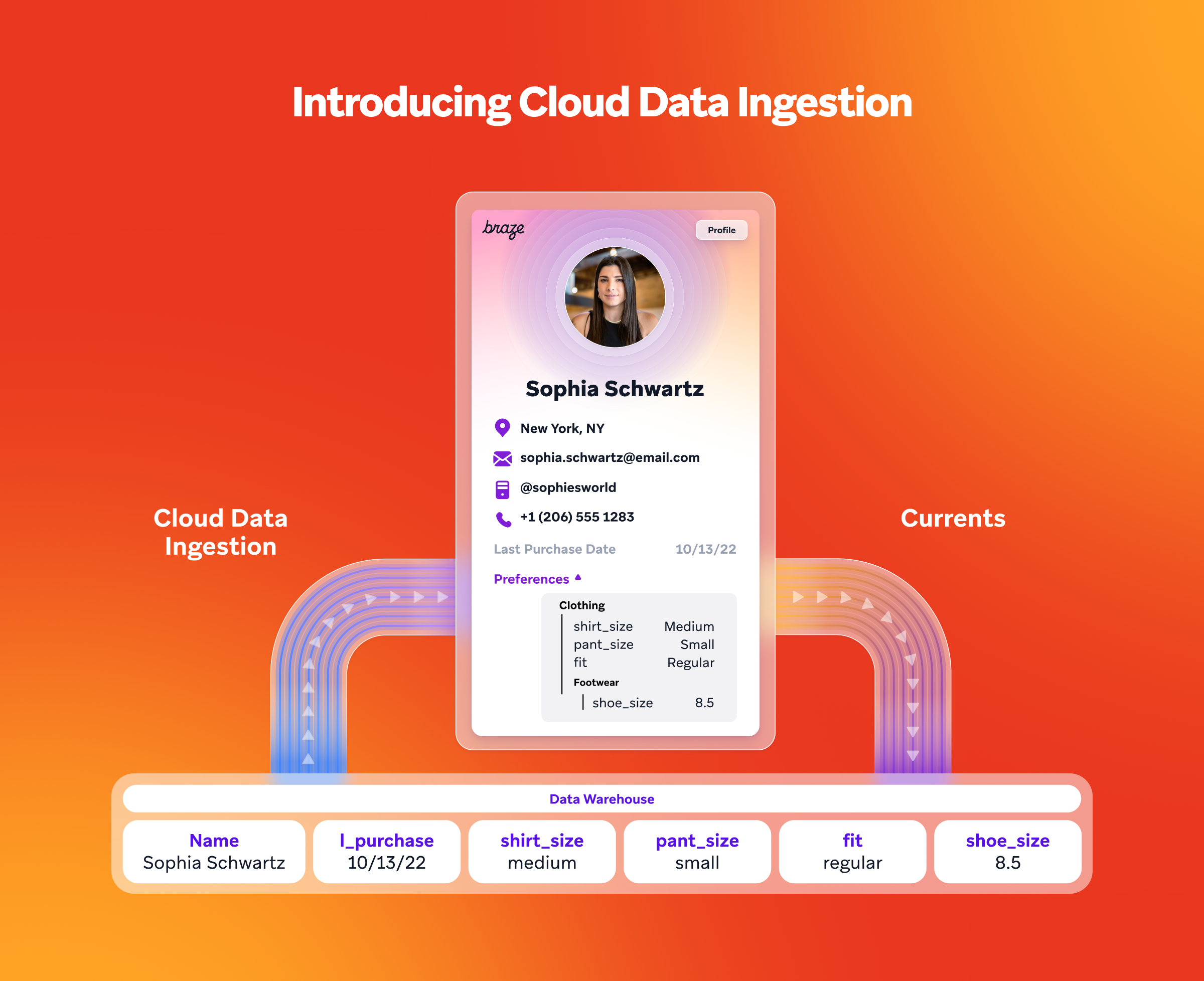
How to set up Cloud Data Ingestion in Braze
As the ecosystem evolves, Braze continues to expand CDI capabilities, including broader data modeling support and deeper integration flexibility across the data warehouse ecosystem.
The setup process typically involves the following steps:
- Prepare and model your data in your data warehouse (e.g. create tables or views that match Braze-supported schemas such as user attributes, events, or purchases)
- Navigate to the relevant CDI section in the Braze dashboard (typically under Data Settings or Technology Partners, depending on the source)
- Create a new Cloud Data Ingestion sync and select your source type (e.g. Snowflake, BigQuery, Redshift, Databricks, or file storage)
- Provide authentication credentials for your data warehouse or storage provider
- Configure the sync by selecting the source table/view, mapping fields to Braze data objects (e.g. users, events, purchases, etc.), and defining the sync behavior
- Set a name and schedule/frequency for the sync (batch-based, not real-time)
- Validate the configuration and run an initial sync/test to ensure data is ingested correctly
Once configured, Braze will automatically run scheduled syncs, allowing you to continuously ingest and update data from your warehouse to support segmentation, personalization, and campaign orchestration across channels such as email, SMS, and mobile/web messaging.
2. Braze Data Transformation
Braze Data Transformation allows brands to build and manage server-side data ingestion workflows using webhook endpoints, enabling integrations with third-party platforms that can send webhooks. This supports a wide range of real-time use cases—brands can receive webhook payloads in Data Transformation and write JavaScript code to transform that data into Braze-supported objects such as user profile updates, events, purchases, or catalog updates.
With Data Transformation, brands can unlock custom data integrations to better activate data, increase operational efficiency, and reduce reliance on engineering resources. In many cases, Data Transformation can help reduce dependency on manual API orchestration, third-party automation tools such as Zapier, and even certain customer data platform (CDP) use cases by enabling direct ingestion and transformation within Braze.
Additionally, Data Transformation features an AI-powered copilot designed to assist users in building transformation logic. Accessible within the workflow, it analyzes incoming webhook payloads and generates JavaScript-based transformation code tailored to the desired Braze data schema, lowering the barrier for teams with limited development resources.
Want to learn more? Check out how Mon-marche.fr uses Braze Data Tranformation to easily activate data to drive more orders.
3. SDKs
At Braze, software development kits (SDKs) serve as a foundational element of our customers’ data ingestion efforts, making it possible to collect detailed data about user attributes and their engagement within a given brand’s mobile app, website, connected TV app, and more into the Braze platform. SDKs can collect nuanced session data and user events as consumers engage with your app/website/etc., supporting audience segmentation, the creation and delivery of campaigns and individualized customer journeys, and other elements of a best-in-class customer engagement program. (Check out the full range of Braze SDKs here.)
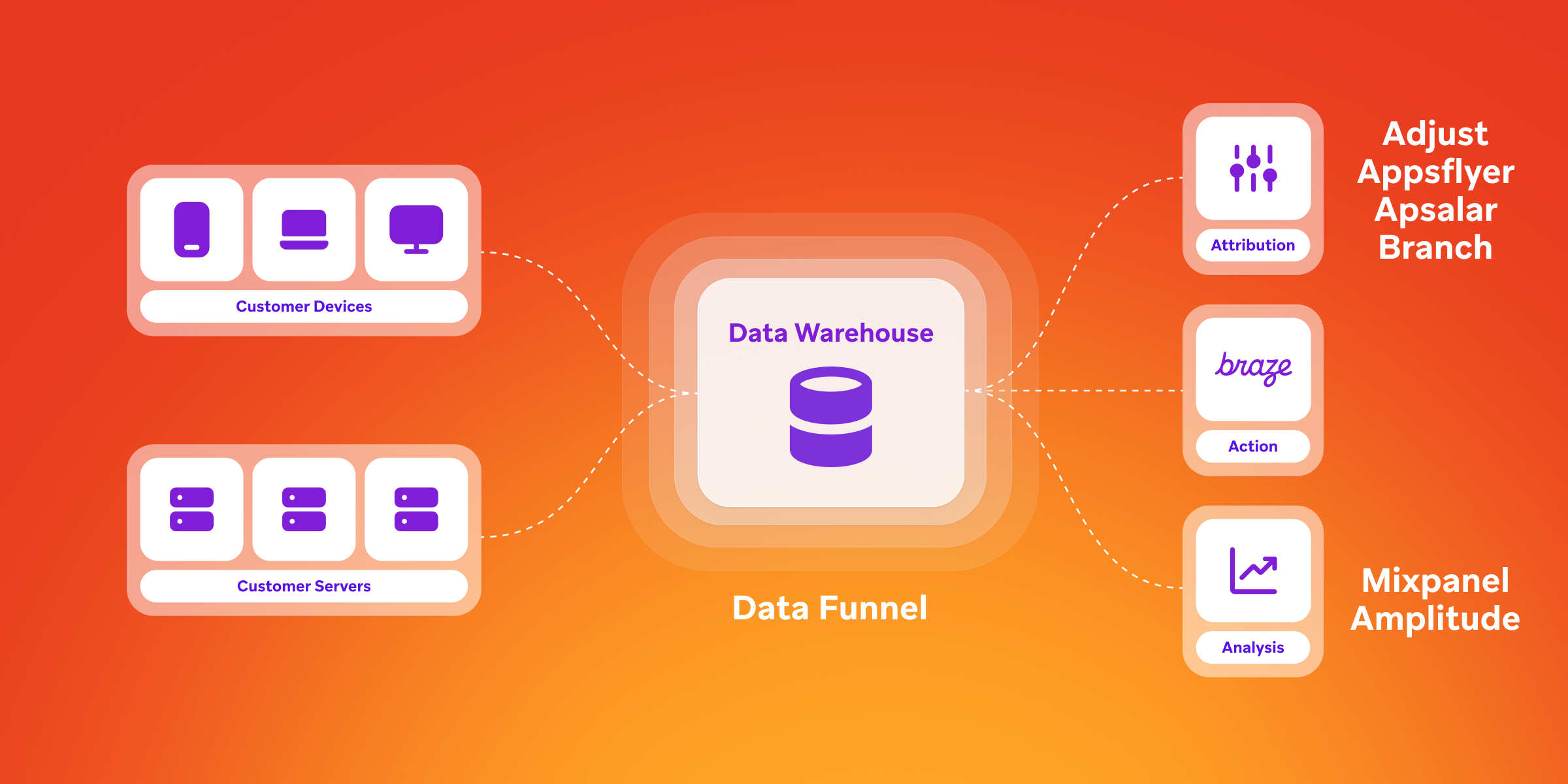
To take advantage of Braze SDKs to support data collection, brands need to integrate them into their app or website. Different levels of data collection will require different approaches to integration, but the baseline integration for Braze SDKs is simple and straightforward, requiring limited engineering support and having minimal impact on app/website sizes. When it comes to scaling, our SDKs are built to handle data at a massive scale, with brands using them to collect and act on information for millions of daily active users without having to worry that they’ll overburden their digital systems.
How does it work? Once the SDK has been integrated into an app or website and you’ve determined what information you want to track, it begins collecting device and session data on any individual engaging with that digital platform, even those whose identities are not known by your brand. Both these so-called “anonymous” users and “known” users (i.e. individuals who have shared their identity with the brand) will automatically have live-updating customer profiles created within Braze, allowing marketers to leverage segmentation, personalization, and triggered messages to reach even anonymous users, supporting a more tailored, meaningful brand experience across the board.
These users are assigned automatically generated anonymous identifiers (device IDs), allowing Braze to associate activity with a temporary profile.
Both anonymous users and known users (i.e., users who have been identified via methods such as external_id) can be engaged within Braze. However, anonymous users are primarily addressable within the same device or session context (for example, via in-app messages or Content Cards), rather than through cross-channel messaging like email or SMS. This enables brands to deliver contextual, real-time experiences even before a user formally identifies themselves.
4. APIs
While SDKs are great when it comes to gathering data directly from the front end of your app or website, sometimes you may want to integrate data from other sources, such as loyalty databases or your own back end. To supplement that foundational element of their data ingestion strategy, many brands turn to application programming interfaces (APIs), which are services designed to handle and respond to requests made between different systems.
In this case, they make it possible for brands to stream information from internal systems and third-party solutions into Braze, complementing the automatic data collection carried out by their SDKs. Our APIs are able to flexibly accept data from almost anywhere, as long as it’s formatted correctly for transmission to Braze and mapped to Braze data objects.
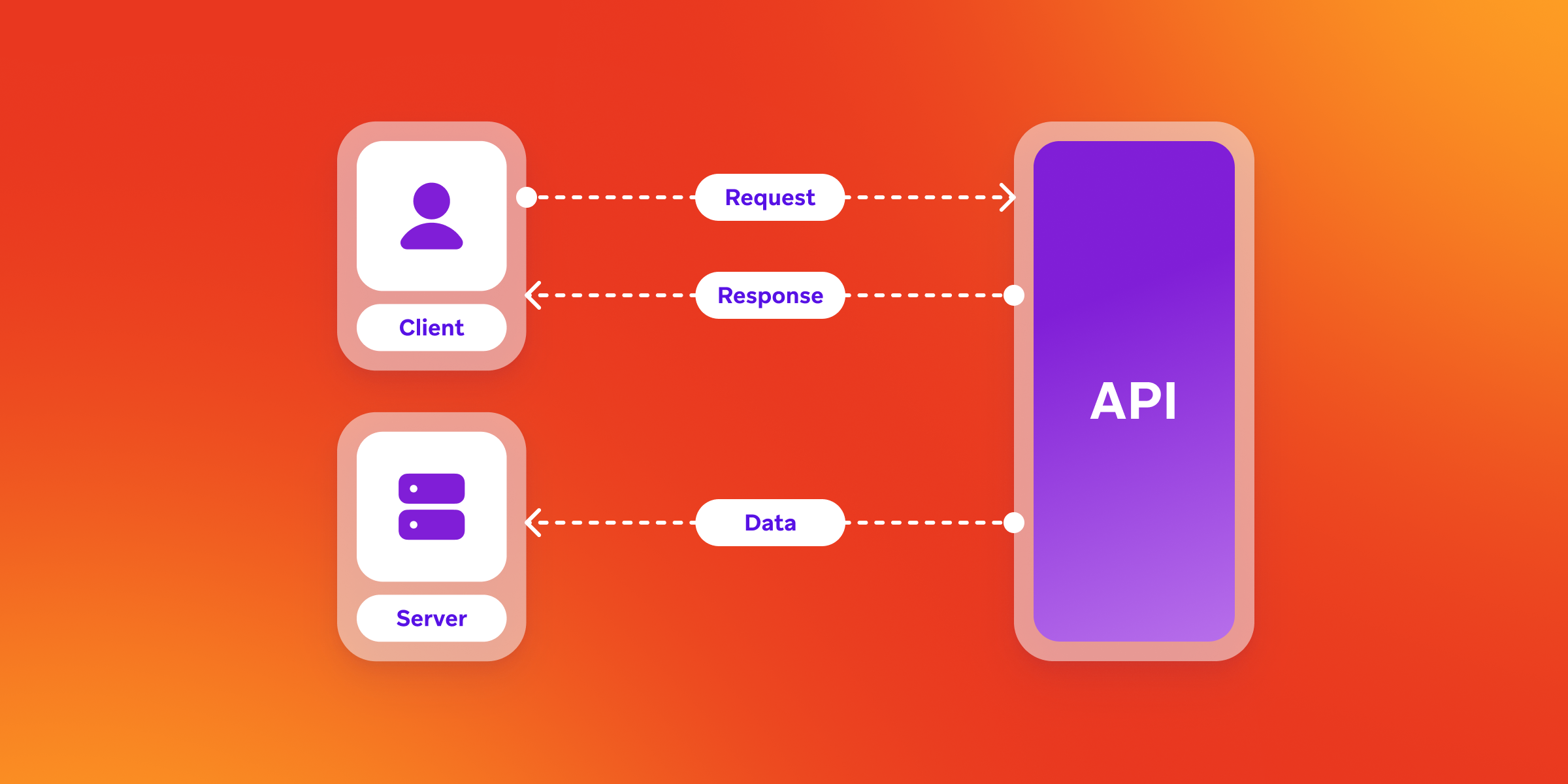
Perhaps the most common use cases we see for API-related data ingestion is when a brand is looking to upload historical data into the Braze platform. In that situation, where a company may have information they’re bringing from a previous customer engagement platform or some other relevant system, the easiest way to make that happen is by leveraging an API to do an initial transfer of user data, create user profiles, and upload users’ push tokens via the Braze platform’s API endpoints. Other use cases include:
- Importing other user information that isn’t being tracked via your SDK into Braze. For instance, point-of-sale (POS) system information, or any other offline data that isn’t directly related to engagement with your app, website, or customer messaging.
- Changing a given consumer’s external user ID, deleting users, or aliasing users within Braze.
While APIs can support a wide variety of ingestion and operational use cases (as well as other needs, such as dynamic content personalization), they are more sensitive to throughput limits and rate limits compared to SDK-based ingestion. For that reason, it’s important to design API-based ingestion with scalability in mind, including batching requests where possible, monitoring rate limits, and considering alternative ingestion methods like Cloud Data Ingestion (CDI) for large-scale data syncs.
5. CSVs
While SDKs and APIs support the vast majority of data ingestion use cases in Braze, the platform also provides a native way to upload data via comma-separated values (CSV) files. This approach is typically best suited for manual, one-time, or low-frequency updates, or for teams that may not yet have the technical resources to implement SDK or API-based ingestion. For example, a team might collect user email addresses in a spreadsheet, export it as a CSV file, and upload it into Braze to create or update user profiles.
CSV uploads can be useful in specific scenarios, but they are not designed for real-time or high-frequency ingestion and are less scalable than SDKs, APIs, or Cloud Data Ingestion (CDI). As such, they are best used for backfills, small-scale updates, or operational workflows managed directly within the Braze dashboard.
Braze enforces file size and processing limits for CSV imports, which can require splitting large datasets into smaller files before upload. To help streamline this process, some teams leverage automation patterns using cloud infrastructure. For example, an open-source AWS-based serverless workflow (using services like Amazon S3 and AWS Lambda) can be used to process large CSV files, split them if needed, and programmatically send the data to Braze via API endpoints.
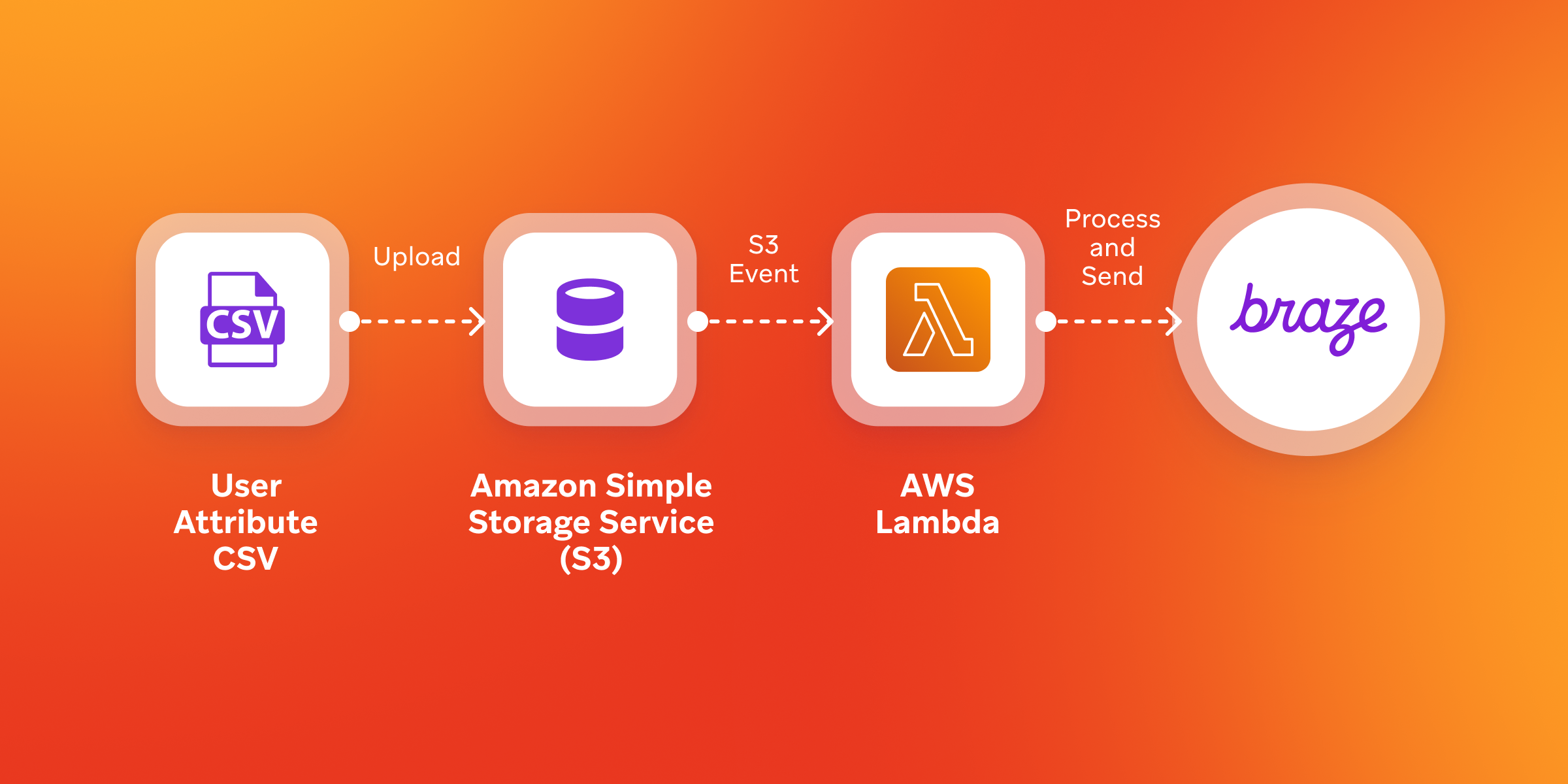
With this approach, brands can upload large CSV files to an S3 bucket, triggering automated processing and ingestion workflows that transform and forward the data into Braze. It’s important to note that this pattern ultimately relies on Braze APIs for ingestion, rather than extending the native CSV upload limits directly. While this can reduce manual effort, it introduces additional infrastructure complexity and is still less efficient than using native, scalable ingestion methods like SDKs, APIs, or CDI.
The upshot? CSV uploads can be a practical tool for quick or non-technical workflows, but for scalable, automated, and real-time data ingestion, brands are strongly encouraged to rely on SDKs, APIs, Data Transformation, or CDI.
6. Braze Technology Partners
Our native data ingestion capabilities—SDKs, APIs, Data Transformation, and Cloud Data Ingestion (CDI)—can be extended through a broad ecosystem of technology partners. These integrations enable brands to move and activate data across their broader tech stack more efficiently, reducing the need for custom-built pipelines.
Braze supports multiple ingestion patterns, including APIs and SDKs for first-party data collection, Cloud Data Ingestion (CDI) for scheduled warehouse and file-based syncing, Data Transformation for webhook-based ingestion, and connected sources for zero-copy segmentation and activation.
Our technology partner ecosystem (available via the Braze Alloys framework) includes several categories of tools that support data ingestion and activation into Braze:
Customer data platforms
Customer data platforms (CDPs) are designed to centralize, unify, and activate customer data across systems. By integrating with Braze, CDPs can streamline data collection and routing, reducing the need for ad hoc ingestion methods (such as CSV uploads) and enabling real-time or near-real-time data forwarding into Braze via APIs and prebuilt connectors.
Analytics solutions
Data analytics platforms are built to allow brands to dive deep into the information at their disposal in order to find hidden insights, better understand high-level trends, and use those discoveries to inform the creation of future experiments, audiences, and segments. By integrating with Braze, these technologies make it possible for brands to leverage the insights and information contained within their analytics provider to support more impactful brand experiences powered by Braze.
Workflow automation and reverse ETL solutions
By leveraging workflow automation and reverse ETL solutions that have direct integrations with Braze, brands can automate the process of reshaping data to ensure that it works within the Braze platform and passing the resulting information into our customer engagement platform.
It’s important to note that many reverse ETL use cases can also be addressed using the Braze platform’s native CDI, depending on requirements around transformation, orchestration, and data ownership.
Final Thoughts
Effective data management is key if you want to make the most of your customer engagement efforts. With Braze, we’ve made that easier by supporting a range of different data ingestion approaches designed to allow you to easily pass key customer data into the Braze platform to support audience segmentation, personalization, triggered campaigns, nuanced testing, and more.
To learn more about how the Braze platform supports data management within a modern marketing technology ecosystem, check out “The marketer’s guide to composable tech stacks.”
Be Absolutely Engaging.™
Sign up for regular updates from Braze.
Related Content
 Article4 min read
Article4 min readThe new CNIL recommendations: Email tracking pixels in France
July 30, 2026 Article6 min read
Article6 min readBuilt to Scale: Announcing the 10 Startups Joining Cohort 6 of Braze Product Grant Program
July 30, 2026 Article6 min read
Article6 min readCrafting authenticity in the age of AI: Insights from hip-hop icon, Common
July 28, 2026